This section assumes that you have a working knowledge of SQL. Navigate the Schema using a SQL Query engine such as MySQL Query Browser or your own custom code. To get a quick start on browsing the schema tables try using the Schema Browser. It allows you to generate queries and view the resulting SQL statements.
The most common navigation need is to retrieve HL7 message data that has been imported into the system. To do this there are 2 tables which will be of extreme importance to you.
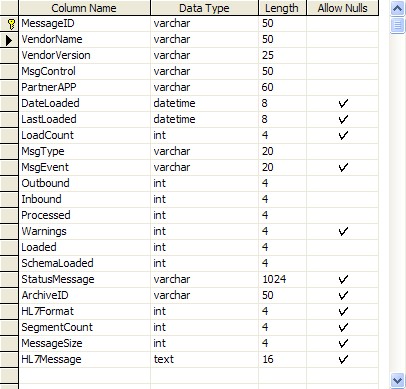
| 1. | The <PREFIX>_HL7Data table. This is the SCHEMA MASTER TABLE. It is the main data warehouse table for your HL7 data. It contains some header information, the MESSAGEID and the entire HL7 message in a Text column. |
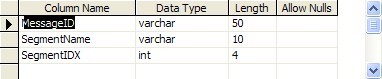
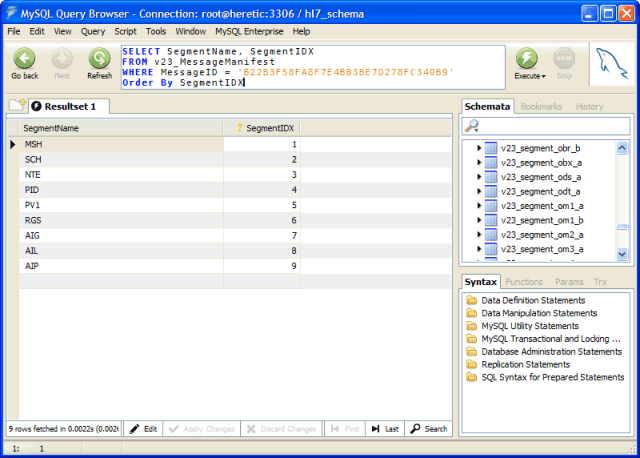
| 2. | The <PREFIX>_MessageManifest table. This table is like a table-of-contents for each HL7 message. It will tell you which HL7 segments were included in the message (from which you can derive which table(s) contain message data) and their sequence within the message. |
The Schema Master Table <prefix>_HL7Data
The Message Manifest table <prefix>_MessageManifest
|
Another important thing you'll need to know before you start retrieving HL7 data elements is how to determine the table and field names which contain the data you're looking for. All of the segment data tables will be dynamically named based on three things, the Schema Prefix, the HL7 Segment Name and the number of HL7 data fields that segment contains. If the HL7 segment contains 40 or more HL7 data fields (like the GT1 [Guarantor Data] or IN1 [Insurance Information] segments), the segment will be represented by two tables.
Example: If the Schema Prefix is V23 the table for the PID (Patient Information) will be named V23_Segment_PID_A. The IN1 (Insurance Information) segment tables would be named V23_Segment_IN1_A which would hold data for fields 1-39 and V23_Segment_IN1_B which would hold data for fields 40-nnn.
The SQL Statement:
Select * from v23_Segment_PID_A Where MessageID = '9A3FF083DE1F384584553969F1745497' Order By IDX
Would return 1 row for each PID segment contained in the message.
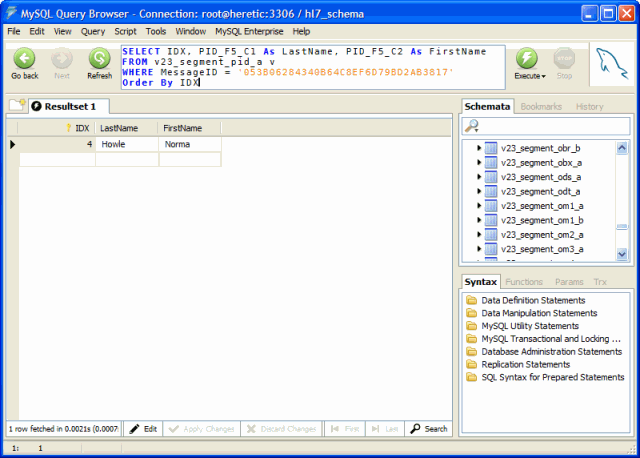
Of equal importance is how to identify which data fields you care about within each table. Here is where some knowledge of HL7 structure is required. As an example we'll use a common field that everyone can relate to: The patient's last name. Assuming a Schema Prefix of v23, to access the patient's last name first you need to know which segment in the message contains it (the PID segment). This gives you the table name v23_Segment_PID_A. To know which field contains the patient's last name you have know which HL7 data field contains the patient name and which specific COMPONENT within that field contains the last name (Field 5 Component 1). Field names within the tables will be derived as <segment>_F<fieldnumber>_C<componentnumber> so the field name for the patient last name is: PID_F5_C1
The SQL Statetment:
SELECT IDX, PID_F5_C1 As LastName, PID_F5_C2 As FirstName
FROM v23_segment_pid_a v
WHERE MessageID = '053B06284340B64C8EF6D79BD2AB3817'
Order By IDX
Would return 1 row containing the patient's last name for each PID segment contained in the message.
The assumption here is that you wish to identify HL7 messages which have been received because you wish to extract some (or all) of the data elements and move/copy them into your primary application database.
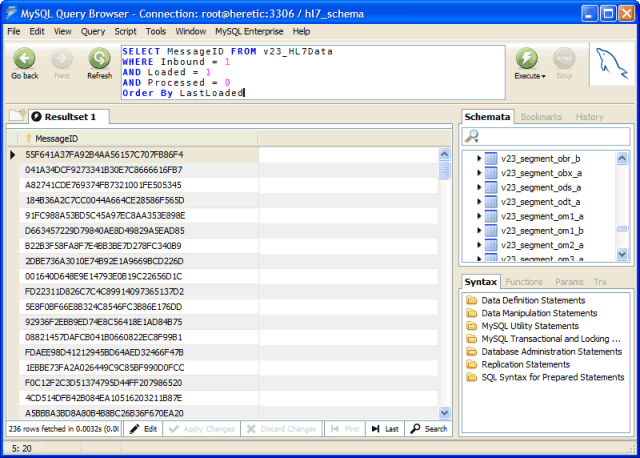
The following SQL Statement will identify messages received, which have had no action taken on them (assumes a Schema Prefix of v23) :
This SQL could obviously be refined to allow you to select only certain message types (WHERE MsgType = 'ADT' )
For each MessageID the following SQL will identify which tables contain HL7 message data.
This identifies the segments which were in the message and the order in which they appeared. From this you can derive the tables which contain HL7 data.
Example: The PID segment table will be named <PREFIX>_Segment_PID_A so assuming a Schema Prefix of v23 the SQL Statement
Select * from v23_Segment_PID_A Where MessageID = '9A3FF083DE1F384584553969F1745497' AND IDX = 3
Would return all data for the PID segment for that message. For the IN1 Segment you would need 2 SQL Statements
Select * from v23_Segment_IN1_A Where MessageID = '9A3FF083DE1F384584553969F1745497' AND IDX = 7 Select * from v23_Segment_IN1_B Where MessageID = '9A3FF083DE1F384584553969F1745497' AND IDX = 7
Q: Why are the SegmentIDX (Manifest) and IDX (All data tables) fields so important?
A: The SegmentIDX field (which translates to the IDX field in the segment data tables) is VERY important. Many messages can have more than 1 instance of certain segments. In the example screenshot above the message contained 1 IN1 segment. It could very easily have contained 2 IN1 segments (1 denoting primary insurance and 1 denoting secondary insurance). Most "results" messages (like lab results etc) contain multiple OBX or OBR segments. So it's important that you be aware that you can either access each row specifically by using the "AND IDX = <nn>" statement OR have your select statement use an Order By IDX clause and be prepared to process more than 1 row.
|
.
Segment: PID-Patient identification segment 30 Fields
# Description Len Type Table #Comp
1 Set ID - PID 4 SI 0 1 2 Patient ID 20 CX 0 6 3 Patient Identifier List 20 CX 0 6 4 Alternate Patient ID - PID 20 CX 0 6 5 Patient Name 48 XPN 0 7 6 Mother's Maiden Name 48 XPN 0 7 7 Date/Time of Birth 26 TS 0 2 8 Sex 1 IS 1 1 9 Patient Alias 48 XPN 0 7 10 Race 80 CE 5 6 11 Patient Address 106 XAD 0 9 12 County Code 4 IS 289 1 13 Phone Number - Home 40 XTN 0 8 14 Phone Number - Business 40 XTN 0 8 15 Primary Language 60 CE 296 6 16 Marital Status 80 CE 2 6 17 Religion 80 CE 6 6 18 Patient Account Number 20 CX 0 6 19 SSN Number - Patient 16 ST 0 1 20 Driver's License Number - Patient 25 DLN 0 3 21 Mother's Identifier 20 CX 0 6 22 Ethnic Group 80 CE 189 6 23 Birth Place 60 ST 0 1 24 Multiple Birth Indicator 1 ID 136 1 25 Birth Order 2 NM 0 1 26 Citizenship 80 CE 171 6 27 Veterans Military Status 60 CE 172 6 28 Nationality 80 CE 212 6 29 Patient Death Date and Time 26 TS 0 2 30 Patient Death Indicator 1 ID 136 1
Data Type: XPN - Extended person name (7 components) Category: Demographics Instructions: 2.8.51 replaces the PN data type. <family name (ST)> ^ <given name (ST)> & <last_name_prefix (ST)> ^ <middle initial or name (ST)> ^ <suffix (e.g., JR or III) (ST)> ^ <prefix (e.g., DR) (ST)> ^ <degree (e.g., MD) (IST)> ^ <name type code Component 1 [ST] family name (last name) Component 2 [ST] given name (first name) Component 3 [ST] middle initial or name Component 4 [ST] suffix (jr, sr, etc) Component 5 [ST] prefix (Mr, Mrs, Dr etc) Component 6 [ST] degree (MD, PHD etc) Component 7 [ID] name type code
|